按照教程https://github.com/kendryte/K230_training_scripts/tree/main/end2end_kws_doc
能成功训练处模型,但是训练的模型无法检测到唤醒词
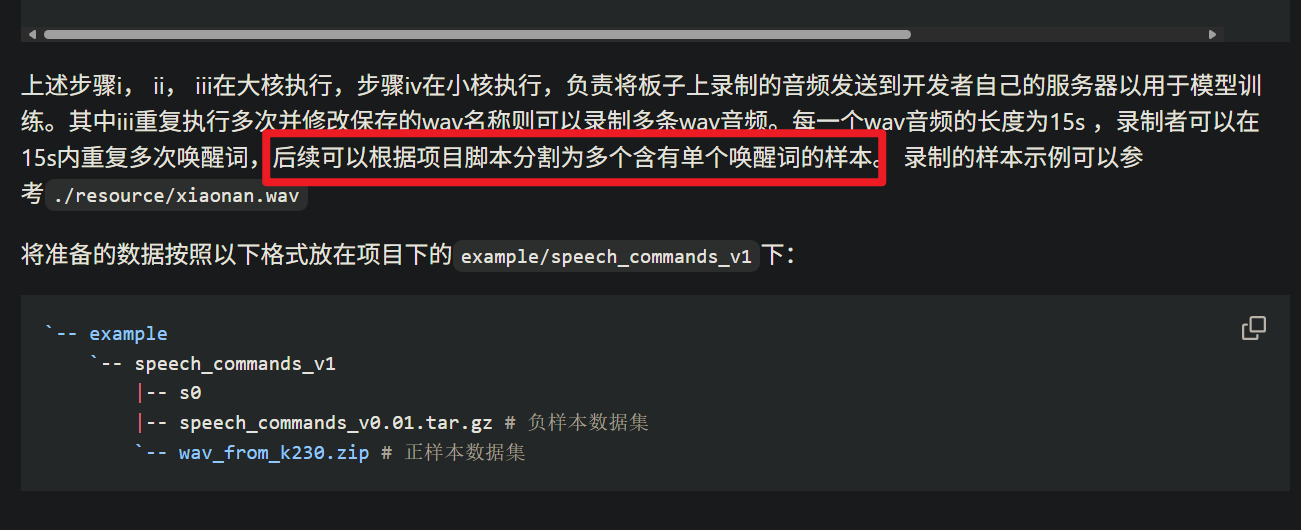
我先录制了一个15秒的音频,15秒内录制了10次唤醒词的内容,然后手动分割成了10个音频文件。
一共录制了六个人的声音,最终用于训练的wav_from_k230压缩包中总共包含60多个音频文件。是否是因为训练的样本数量太少了导致无法唤醒?
===========================
补充教程图片