我在官方 GitHub 上发现了类似的问题,里面提到在模型里开启 nms
https://github.com/ultralytics/ultralytics/issues/19088
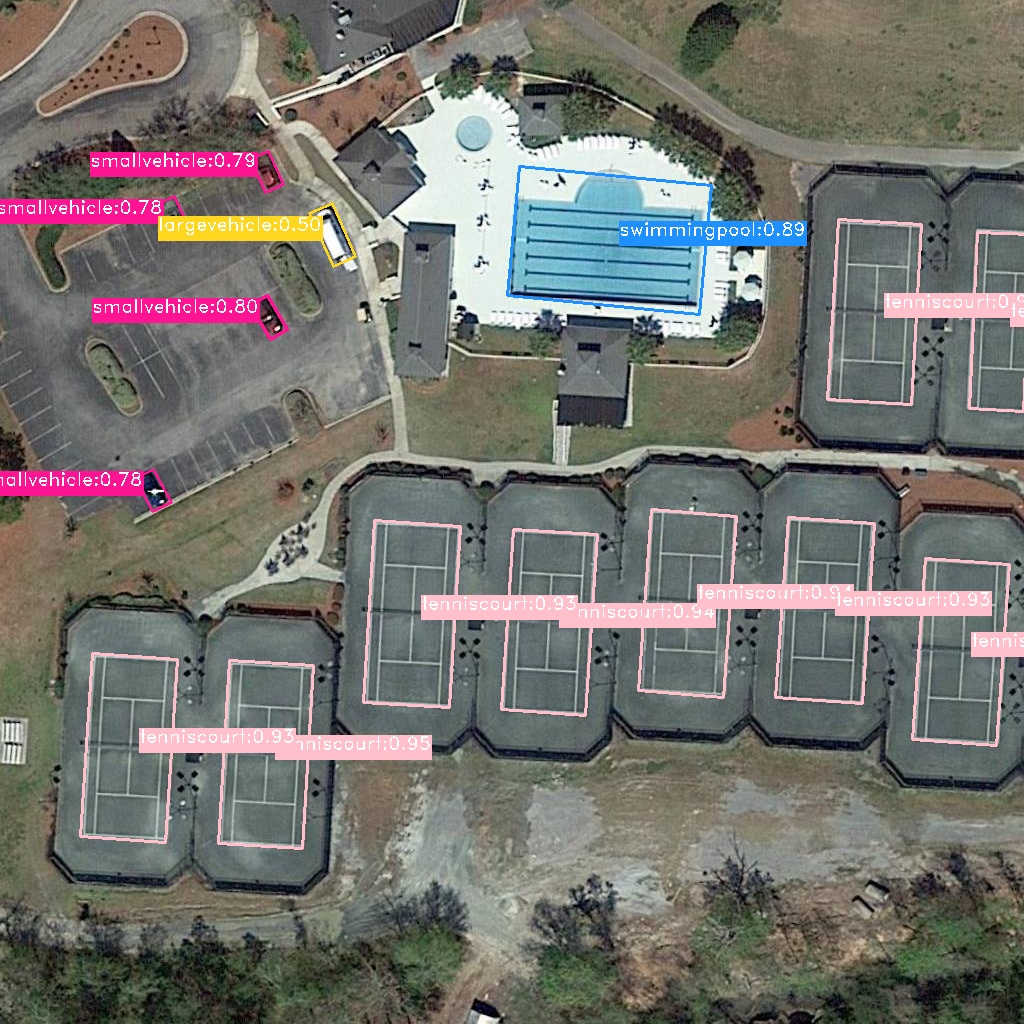
下面是我处理的一些步骤
把 yolo11n-obb.pt 转成 yolo11n-obb.onnx 并开启 nms
yolo export model=yolo11n-obb.pt format=onnx nms=True
运行下面的 python 程序测试模型输出
import cv2
import numpy as np
import onnxruntime as ort
if __name__ == "__main__":
# 加载模型
session = ort.InferenceSession("yolov8n-obb.onnx", providers=["CPUExecutionProvider"])
# 获取输入输出信息
for input in session.get_inputs():
print(f"Input Name: {input.name}, Shape: {input.shape}, Type: {input.type}")
for output in session.get_outputs():
print(f"Output Name: {output.name}, Shape: {output.shape}, Type: {output.type}")
# 1. 加载测试图像并预处理
img = cv2.imread("boats.jpg")
blob = cv2.dnn.blobFromImage(img, 1/255.0, (1024, 1024), swapRB=True)
# 2. 运行推理
outputs = session.run(None, {session.get_inputs()[0].name: blob})
# 3. 分析输出
print("输出张量形状:", outputs[0].shape) # 例如 (1, 10, 6)
print("示例输出数据(前3个检测结果):\n", outputs[0][0, :3, :])
输出结果
Input Name: images, Shape: [1, 3, 1024, 1024], Type: tensor(float)
Output Name: output0, Shape: [1, 300, 7], Type: tensor(float)
输出张量形状: (1, 300, 7)
示例输出数据(前3个检测结果):
[[9.5551410e+02 5.4617480e+02 7.8908127e+01 2.7469975e+01 8.4804726e-01
1.0000000e+00 7.3035687e-01]
[9.4972351e+02 5.8845270e+02 7.3113594e+01 2.6608990e+01 8.4455013e-01
1.0000000e+00 6.6087908e-01]
[8.6364545e+02 9.5005072e+02 7.6179825e+01 2.9771505e+01 8.3805233e-01
1.0000000e+00 6.6160357e-01]]

我在官方 GitHub 上发现了类似的问题,里面提到在模型里开启 nms
https://github.com/ultralytics/ultralytics/issues/19088